Maintenant que nous avons exécuté son scénario de tir de charge par paliers, il faut s’occuper des résultats. Nous allons utiliser Microsoft Access pour ce travail.
Mise à jour 26/10/2008 : Ici un billet pour faire des graphiques avec Gnuplot.
Etape 7 : Insertion des résultats dans Access
Si on regarde le fichier de résultats avec un éditeur de texte, on trouve un résultat par ligne, avec des champs séparés par le caractère point-virgule (qui a été judicieusement placé).
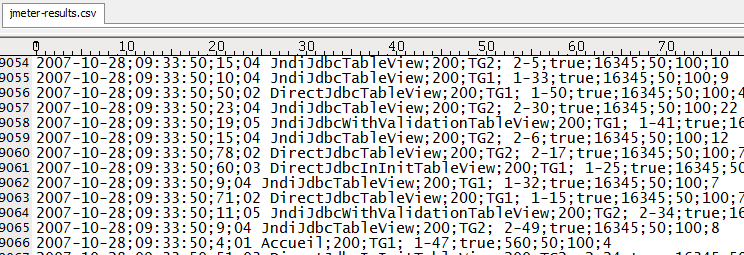
Nous allons importer ce fichier CSV dans le logiciel Microsoft Access version 2007 (mais cela doit fonctionner aussi avec les versions précédentes d’Access). On notera qu’il est possible de faire la même chose avec Excel, la seule contrainte est la limitation du nombre de ligne d’une feuille Excel à 65535, donc le résultat du tir doit faire moins de 65535 lignes. Ici ce n’est pas le cas avec plus de 140000 lignes. Access est donc le meilleur choix.
Une petite note : malheureusement avec OpenOffice Base, la fonction table pivot (tableau croisé dynamique) n’est pas disponible (du moins je ne l’ai pas trouvée).
Donc, on lance Microsoft Access 2007, et on créé une nouvelle base vierge. On se place sur l’onglet External Data, puis on clique sur le bouton Text File.
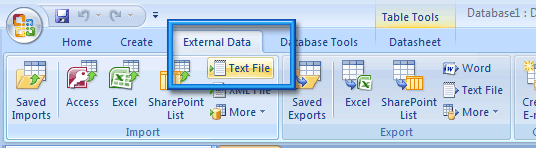
Une nouvelle fenêtre apparaît, dans le champ File name on indique le chemin et le nom du fichier CSV (ici C:\jmeter-results.csv), et on choisit l’option Import the source data into a new table in the current database, puis on passe à l’étape suivante.
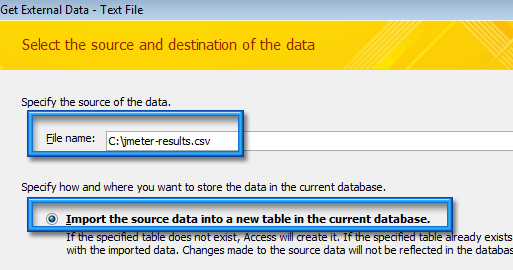
Dans la nouvelle fenêtre, on choisit le type de séparation de champs à délimitée (Delimited).
Le délimiteur est le point-virgule (Semicolon).
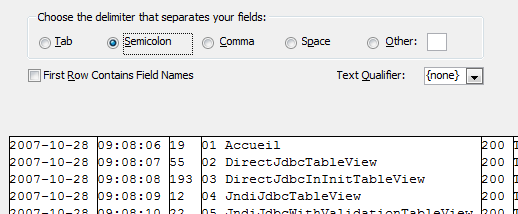
Sur le nouvel écran, on va directement sur le bouton Advanced.
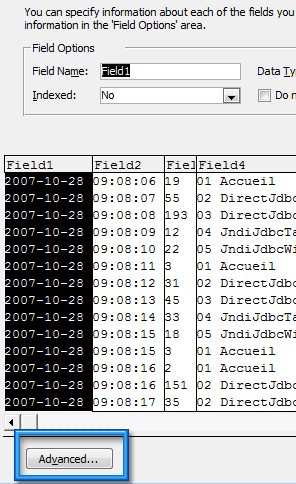
Et dans la nouvelle fenêtre, nous allons définir quelques options d’importations :
- Le format de la date à YMD et avec le délimiteur « – »
- Le nom des champs (cf. capture)
- Le type de champs pour ID Unités à Text et Résultat à Yes/No.
Ci-dessous la fin des noms des champs.
Sur l’écran de l’assistant de demande de clé primaire, on choisira aucune clé primaire.

Voilà, la dernière étape, sera le nom de table.

Access fait donc l’importation du fichier texte dans la base. Ci-dessous le resultat.
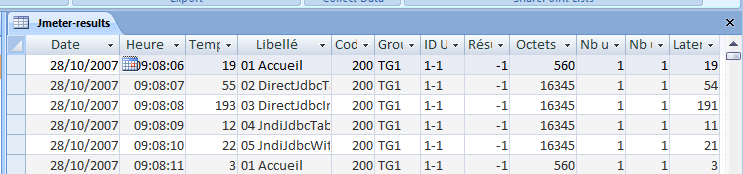
Etape 8 : Génération du graphique avec Access
Maintenant que les données sont dans Access, nous allons utiliser une fonctionnalité bien pratique pour générer des graphiques sans trop d’efforts : les tables pivot (tableaux croisés dynamiques). Pour cela, on se place sur l’onglet du nom de la table, bouton droit de la souris, puis on choisit l’option PivotChart View.
On bascule vers un mode graphique.
Une fenêtre de liste de champ apparaît également. Nous allons l’utiliser pour générer le graphe, en sélectionnant le champ et en le déplaçant vers les zones prévues à ce effet sur le graphique.
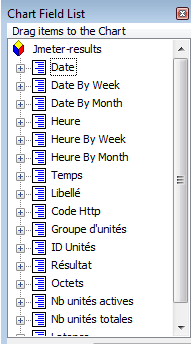
On choisira donc :
- Le champ Temps vers la zone en haut du graphique (pas celle tout en haut, mais juste au dessus de la zone grise du graphique)
- Le champ Nb unités totales vers la même zone en haut du graphique
- Le champ Libellé vers la zone à droite
- Le champ Heure vers la zone en bas
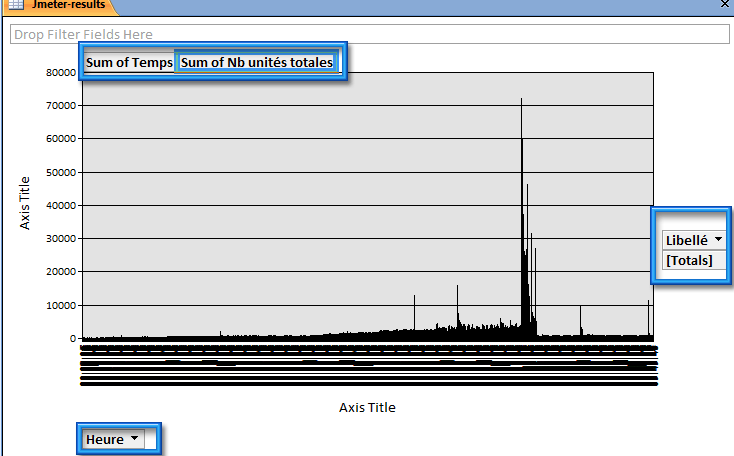
Ensuite quelques changements, on se place sur l’élément Sum Of Temps, bouton droit de la souris, menu AutoCalc > Average (moyenne)
On fait la même chose pour l’élément Sum Of Nb unités totales.
Ensuite on se place sur l’élément Heure, bouton droit de la souris, menu Properties.
Dans la nouvelle fenêtre, on se place sur l’onglet Filter and Group, et dans la partie Grouping, pour le champ Group items by on choisira Minutes.

On va aussi changer le type de graphique. Sur l’onglet Design, on clique sur le bouton Change Chart Type.
On choisira le type de graphique à Line, puis le premier type.
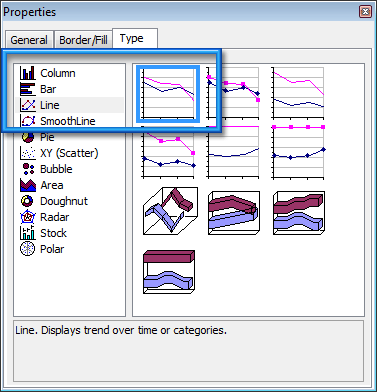
Pour finir, nous allons faire quelques ajustements sur le graphique. Pour cela, on se place sur le haut du graphique avec sa souris (cf. capture), puis bouton droit de la souris, menu Properties.
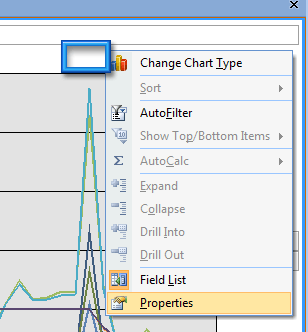
Dans la nouvelle fenêtre, on se place sur l’onglet Series Groups, puis dans le champ Select one or more series, on choisit la deuxième ligne (01 Accueil), puis on clique sur le bouton OK (situé à droite).
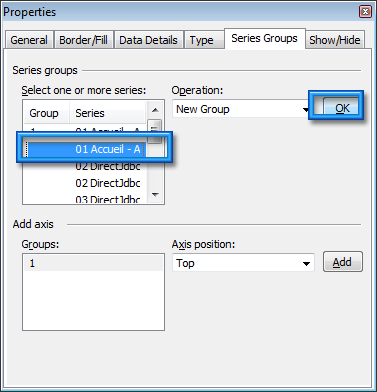
On reste sur la même fenêtre et même onglet. Dans le champ Groups, on sélectionne la deuxième ligne « 2 », puis dans le champ Axis position, on choisit Right, puis on clique sur le bouton Add.
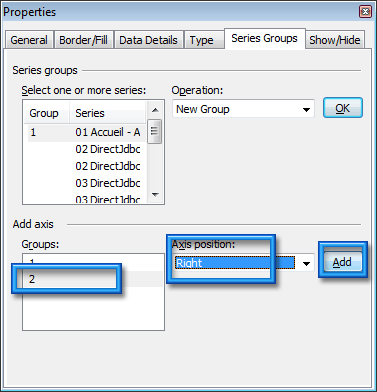
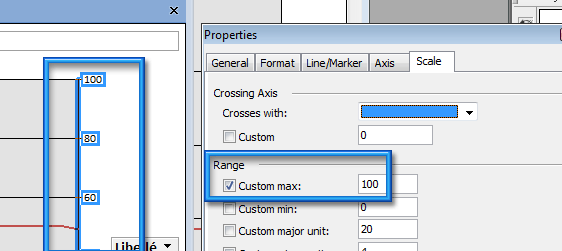
Un dernier changement sera la mise à l’échelle du l’axe de droite pour correspondre à l’axe de gauche. Ce n’est pas obligatoire (c’est en fonction de votre résultat).
Pour cela, on sélectionne cet axe, puis bouton droit de la souris, menu Properties. Dans la nouvelle fenêtre, on va dans l’onglet Scale. Puis dans la zone Range, on personnalise le champ Custom max en mettant 100.
Voici le graphique « final ». La courbe rouge montre le nombre des unités d’exécutions actives durant le test, et les autres courbes montrent les temps de réponses des différents servlets.
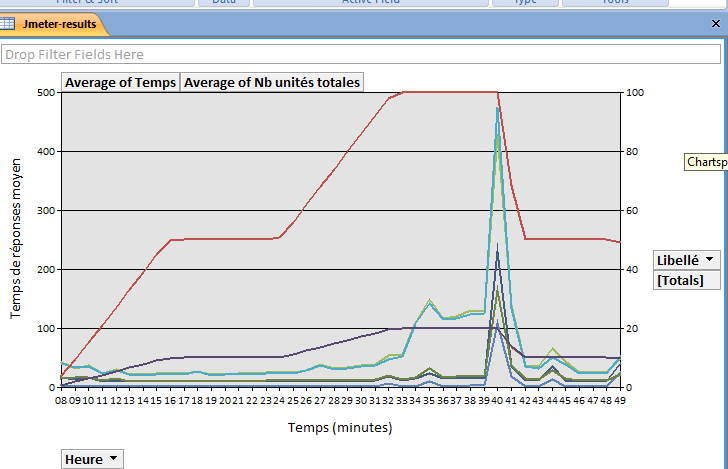
Maintenant il faut passer à l’analyse de ce graphique. C’est un art difficile de manière générale car cela dépend de pas mal de paramètres. On peut néanmoins voir très rapidement avec ce graphique
- qu’il y a une relation de cause à effet par rapport aux temps de réponses en fonction de la charge ;
- que les périodes de montée en charge (la première et la seconde) montrent des temps de réponses plus longs que pendant un palier constant (ce qui est normal en général, car ici Tomcat et la base MySQL s’adaptent progressivement à la charge en augmentant leurs ressources (mémoire JVM, nombre de process, etc), ce qui prend du temps CPU) ;
- que l’impact du doublement des utilisateurs est beaucoup moins importants sur les servlets utilisant JNDI/JDBC (pool de connexions à la base) qui les servlets faisant un accès direct à la base. (peut-être une histoire de cache ?) ;
- que l’on revient bien à une situation normale en termes de temps de réponse après le retour à 50 utilisateurs ;
- etc.
Bien entendu, il s’agit d’un seul graphique, on peut modifier ce graphique pour faire ressortir d’autres « effets ».
Bon courage./
Bonjour,
En fait, suite à la refonte de notre application (.aspx) , lorsqu’on effectue un tir de charge (1GU avec 1seul utilisateur qui répète infiniment 4URL (s) pendant 500secondes) et on trace le graphique comme c’est indiqué dans la procédure de votre site:
1- pourcentage d’erreur élevé,
2- code http relatif à toutes les erreurs= 500
3- valeurs de temps de réponses négatives
En fait, le point (2) est interprété par une couche de persistance de données moyenne.
Voyez vous comment s’interprètent les valeurs négatives de temps de réponse?
Merci en avance.